This post originally was submitted to the Java Advent Calendar and is licensed under the Creative Commons 3.0 Attribution license. If you like it, please spread the word by sharing, tweeting, FB, G+ and so on!
picking up Peters well written overview on the uses of Unsafe, i'll have a My major point is to show that conversion of Objects to bytes and vice versa is an important fundamental, affecting virtually any modern java application.
Hardware enjoys to process streams of bytes, not object graphs connected by pointers as "All memory is tape" (M.Thompson if I remember correctly ..).
Many basic technologies are therefore hard to use with vanilla Java heap objects:
- Memory Mapped Files - a great and simple technology to persist application data safe, fast & easy.
- Network communication is based on sending packets of bytes
- Interprocess communication (shared memory)
- Large main memory of today's servers (64GB to 256GB). (GC issues)
- CPU caches work best on data stored as a continuous stream of bytes in memory
- [performance enhanced] object serialization or
- wrapper classes to ease access to data stored in a continuous memory region.
Serialization based Off-Heap
Consider a retail WebApplication where there might be millions of registered users. We are actually not interested in representing data in a relational database as all needed is a quick retrieve of user related data once he logs in. Additionally one would like to traverse the social graph quickly.
Let's take a simple user class holding some attributes and a list of 'friends' making up a social graph.

easiest way to store this on heap, is a simple huge HashMap.
Serialization is used to store objects, deserialization is used in order to pull them to the java heap again. Pleasantly I have written the (afaik) fastest fully JDK compliant object serialization on the planet, so I'll make use of that.

Done:
- persistence by memory mapping a file (map will reload upon creation).
- Java Heap still empty to serve real application processing with Full GC < 100ms.
- Significantly less overall memory consumption. A user record serialized is ~60 bytes, so in theory 300 million records fit into 180GB of server memory. No need to raise the big data flag and run 4096 hadoop nodes on AWS ;).
Comparing a regular in-memory java HashMap and a fast-serialization based persistent off heap map holding 15 millions user records, will show following results (on a 3Ghz older XEON 2x6):
| consumed Java Heap (MB) | Full GC (s) | Native Heap (MB) | get/put ops per s | required VM size (MB) | |
| HashMap | 6.865,00 | 26,039 | 0 | 3.800.000,00 |
12.000,00
|
| OffheapMap (Serialization based) |
63,00
|
0,026
|
3.050
|
750.000,00
|
500,00
|
[test source / blog project] Note: You'll need at least 16GB of RAM to execute them.

Use of JDK serialization would perform at least 5 to 10 times slower (direct comparison below) and therefore render this approach useless.

Using a fast implementation, its possible to generously use (fast-) serialization for over-the-network messaging. Again: if this would run like 5 to 10 times slower, it just wouldn't be viable. Alternative approaches require an order of magnitude more work to achieve similar results.
By wrapping the persistent off heap hash map by an Actor implementation (async ftw!), some lines of code make up a persistent KeyValue server with a TCP-based and a HTTP interface (uses kontraktor actors). Of course the Actor can still be used in-process if one decides so later on.

Now that's a micro service. Given it lacks any attempt of optimization and is single threaded, its reasonably fast [same XEON machine as above]:
- 280_000 successful remote lookups per second
- 800_000 in case of fail lookups (key not found)
- serialization based TCP interface (1 liner)
- a stringy webservice for the REST-of-us (1 liner).
A real world implementation might want to double performance by directly putting received serialized object byte[] into the map instead of encoding it twice (encode/decode once for transmission over wire, then decode/encode for offheaping map).
"RestActorServer.Publish(..);" is a one liner to also expose the KVActor as a webservice in addition to raw tcp:

C like performance using flyweight wrappers / structs
With serialization, regular Java Objects are transformed to a byte sequence. One can do the opposite: Create wrapper classes which read data from fixed or computed positions of an underlying byte array or native memory address. (E.g. see this blog post).
By moving the base pointer its possible to access different records by just moving the the wrapper's offset. Copying such a "packed object" boils down to a memory copy. In addition, its pretty easy to write allocation free code this way. One downside is, that reading/writing single fields has a performance penalty compared to regular Java Objects. This can be made up for by using the Unsafe class.

Fast-serializaton provides a byproduct "struct emulation" supporting creation of flyweight wrapper classes from regular Java classes at runtime. Low level byte fiddling in application code can be avoided for the most part this way.
How a regular Java class can be mapped to flat memory (fst-structs):

{kind=link}
Of course there are simpler tools out there to help reduce manual programming of encoding (e.g. Slab) which might be more appropriate for many cases and use less "magic".
What kind of performance can be expected using the different approaches (sad fact incoming) ?
Lets take the following struct-class consisting of a price update and an embedded struct denoting a tradable instrument (e.g. stock) and encode it using various methods:

a 'struct' in code
Pure encoding performance:
| Structs | fast-Ser (no shared refs) | fast-Ser | JDK Ser (no shared) | JDK Ser |
| 26.315.000,00 | 7.757.000,00 | 5.102.000,00 | 649.000,00 | 644.000,00 |

Real world test with messaging throughput:
In order to get a basic estimation of differences in a real application, i do an experiment how different encodings perform when used to send and receive messages at a high rate via reliable UDP messaging:
The Test:
A sender encodes messages as fast as possible and publishes them using reliable multicast, a subscriber receives and decodes them.
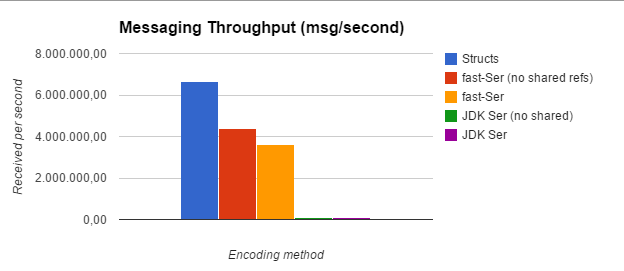
| Structs | fast-Ser (no shared refs) | fast-Ser | JDK Ser (no shared) | JDK Ser |
| 6.644.107,00 | 4.385.118,00 | 3.615.584,00 | 81.582,00 | 79.073,00 |

"
...
***** Stats for receive rate: 80351 per second *********
***** Stats for receive rate: 78769 per second *********
SUB-ud4q has been dropped by PUB-9afs on service 1
fatal, could not keep up. exiting
"
(Creating backpressure here probably isn't the right way to address the issue ;-) )
Conclusion:
- a fast serialization allows for a level of abstraction in distributed applications impossible if serialization implementation is either
- too slow
- incomplete. E.g. cannot handle any serializable object graph
- requires manual coding/adaptions. (would put many restrictions on actor message types, Futures, Spore's, Maintenance nightmare) - Low Level utilities like Unsafe enable different representations of data resulting in extraordinary throughput or guaranteed latency boundaries (allocation free main path) for particular workloads. These are impossible to achieve by a large margin with JDK's public tool set.
- In distributed systems, communication performance is of fundamental importance. Removing Unsafe is not the biggest fish to fry looking at the numbers above .. JSON or XML won't fix this ;-).
- While the HotSpot VM has reached an extraordinary level of performance and reliability, CPU is wasted in some parts of the JDK like there's no tomorrow. Given we are living in the age of distributed applications and data, moving stuff over the wire should be easy to achieve (not manually coded) and as fast as possible.
Addendum: bounded latency


[credits: charts+measurement done with HdrHistogram]
This is an "experiment" rather than a benchmark (so do not read: 'Proven: Java faster than C'), it shows low-level-Java can compete with C in at least this low-level domain.
Of course its not exactly idiomatic Java code, however its still easier to handle, port and maintain compared to a JNI or pure C(++) solution. Low latency C(++) code won't be that idiomatic either ;-)
About me: I am a solution architect freelancing at an exchange company in the area of realtime GUIs, middleware, and low latency CEP (Complex Event Processing) nightly hacking at https://github.com/RuedigerMoeller.