In order to avoid heavy impact of long lived data on OldGen GC, there are several workarounds/techniques.
- Put large parts of mostly static data Off-Heap using ByteBuffer.allocateDirect() or Unsafe.allocateMemory(). This memory is then used to store data (e.g. by using a fast serialization like http://code.google.com/p/fast-serialization/ [oops, I did it again] or specialized solutions like http://code.google.com/p/vanilla-java/wiki/HugeCollections ).
Downside is, that one frequently has to implement a manual memory mangement on top. - "instance saving" on heap by serializing into byte-arrays or transformation of datastructures. This usually involves using open adressed hashmaps without "Entry" Objects, large primitive arrays instead of small Objects like
class ReferenceDataArray {
int x[];
double y[];
long z[];
public ReferenceDataArray(int size) {
x = new int[size];
y = new ...;
z = ...;
}
public long getZ(int index) { return z[index]; }
},
replacement of generic collections with <Integer>, <Long> by specialized implementations with direct primitve int, long, ..
If its worth to cripple your code this way is questionable, however the option exists.
Going the route outlined in (2) improves the effectivity of OldGen GC a lot. FullGC duration can be in the range of 2s even with heap sizes in the 8 GB area. CMS performs significantly better as it can scan OldSpace faster and therefore needs less headroom in order to avoid Full GC.
However there is still the fact, that YoungGen GC scales with OldSpace size.
The scaling effect is usually associated with "cardmarking". Young GC has to remember which areas of OldSpace have been modified (in such a way they reference objects in YoungGen). This is done with kind of a BitField where each bit (or byte) denotes the state of (modified/reference created or similar) a chunk ("card") of OldSpace.
Primitive Arrays basically are BLOBS for the VM, they cannot contain a reference to other Java Objects, so theoretically there is no need to scan or card-mark areas containing BLOBS them when doing GC. One could think e.g. of allocating large primitive arrays from top of oldspace, other objects from bottom this way reducing the amount of scanned cards.
Theory: blobs (primitive arrays) result in shorter young GC pauses then equal amount of heap allocated in smallish Objects.
Therefore I'd like to do a small test, measuring the effects of allocating large primitive arrays (such as byte[], int[], long[], double[]) on NewGen GC duration.
The Test
public class BlobTest {
static ArrayList blobs = new ArrayList();
static Object randomStuff[] = new Object[300000];
public static void main( String arg[] ) {
if ( Runtime.getRuntime().maxMemory() > 2*1024*1024*1024l) { // 'autodetect' avaiable blob space from mem settings
int blobGB = (int) (Runtime.getRuntime().maxMemory()/(1024*1024*1024l));
System.out.println("Allocating "+blobGB*32+" 32Mb blobs ... (="+blobGB+"Gb) ");
for (int i = 0; i < blobGB*32; i++) {
blobs.add(new byte[32*1024*1024]);
}
System.gc(); // force VM to adapt ..
}
// create eden collected tmps with a medium promotion rate (promotion rate can be adjusted by size of randomStuff[])
while( true ) {
randomStuff[((int) (Math.random() * randomStuff.length))] = new Rectangle();
}
}
}
The while loop at the bottom simulates the allocating application. Because I rewrite random indizes of the randomStuff arrays using a random index, a lot of temporary objects are created, because they same index is rewritten with another object instance. However because of random, some indices will not be hit in time and live longer, so they get promoted. The larger the array, the less likely index overwriting gets, the higher the promotion rate to OldSpace.
In order to avoid bias by VM-autoadjusting, I pin NewGen sizes, so the only variation is the allocation of large byte[] on top the allocation loop. (Note these settings are designed to encourage promotion, they are in now way optimal).
commandline:
java -Xms1g -Xmx1g -verbose:gc -XX:-UseAdaptiveSizePolicy -XX:SurvivorRatio=12 -XX:NewSize=100m -XX:MaxNewSize=100m -XX:MaxTenuringThreshold=2
by adding more GB the upper part of the test will use any heap above 1 GB to allocate byte[] arrays.
java -Xms3g -Xmx3g -verbose:gc -XX:-UseAdaptiveSizePolicy -XX:SurvivorRatio=12 -XX:NewSize=100m -XX:MaxNewSize=100m -XX:MaxTenuringThreshold=2
...
...
java -Xms11g -Xmx11g -verbose:gc -XX:-UseAdaptiveSizePolicy -XX:SurvivorRatio=12 -XX:NewSize=100m -XX:MaxNewSize=100m -XX:MaxTenuringThreshold=2
I am using byte[] arrays in the test, I verified int[], long[] behave exactly the same (must apply divisor then to adjust for larger size).
Results
(jdk 1.7_u21)
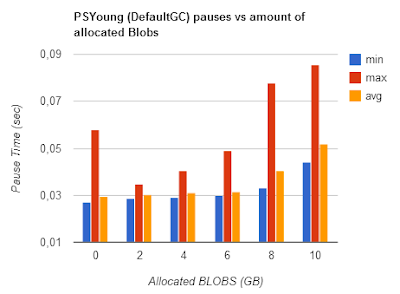

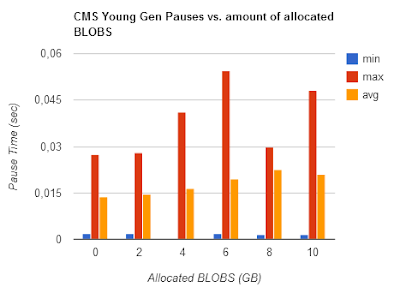


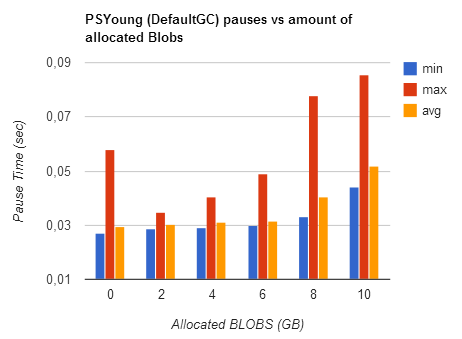




The 'Objects' test was done by replacing the static byte[] allocation loop in the benchmark by
for ( int i = 0; i < blobGB*2700000; i++ )
nonblobs.add(new Object[] {
new Rectangle(),new Rectangle(),new Rectangle(),
new Rectangle(),new Rectangle(),new Rectangle(),
new Rectangle(),new Rectangle(),new Rectangle(),
new Rectangle()});
new Rectangle(),new Rectangle(),new Rectangle(),
new Rectangle(),new Rectangle(),new Rectangle(),
new Rectangle(),new Rectangle(),new Rectangle(),
new Rectangle()});
Conclusion
Flattening data structures using on-heap allocated primitive arrays ('BLOBS') reduces OldGen GC overhead very effective.
Young Gen pauses slightly reduce for CMS, so scaling with OldGen size is damped but not gone. For DefaultGC (PSYoung), minor pauses are actually slightly higher when the heap is filled with BLOBs.
I am not sure if the observed young gen duration variance has anything to do with "card marking" however i am satisfied quantifying effects of different allocation types and sizes :-)
Further Improvement incoming ..
With this genious little optimization coming up in JDK 7_u40
card scanning of unmarked cards speeds up by a factor of 8.
Additonally notice
At least CMS Young Gen pause scaling is not too bad.

And G1 ?
G1 fails to execute the test. If one only allocates 6GB of byte[] with 11GB of heap, it still is much more disruptive than CMS. It works if I use small byte[] chunks of 1MB size and set page size to 32MB. Even then pauses are longer compared to CMS. G1 seems to have problems with large object arrays which will be problematic for IO intensive applications requiring big and many byte buffers.
Great Article… I love to read your articles because your writing style is too good, its is very very helpful for all of us
ReplyDeleteou will get an introduction to the Python programming language and understand the importance of it. How to download and work with Python along with all the basics of Anaconda will be taught. You will also get a clear idea of downloading the various Python libraries and how to use them.
Topics
About ExcelR Solutions and Innodatatics
Do's and Don’ts as a participant
Introduction to Python
Installation of Anaconda Python
Difference between Python2 and Python3
Python Environment
Operators
Identifiers
Exception Handling (Error Handling)
Excelr Solutions
I love your article so much. Good job
ReplyDeleteParticipants who complete the assignments and projects will get the eligibility to take the online exam. Thorough preparation is required by the participants to crack the exam. ExcelR's faculty will do the necessary handholding. Mock papers and practice tests will be provided to the eligible participants which help them to successfully clear the examination.
Excelr Solutions
Nice Presentation and its hopefull words..
ReplyDeleteif you want a cheap web hosting in web
crm software development company in chennai
erp software development company in chennai
Professional webdesigning company in chennai
best seo company in chennai
This comment has been removed by the author.
ReplyDeleteI learned World's Trending Technology from certified experts for free of cost. I got a job in decent Top MNC Company with handsome 14 LPA salary, I have learned the World's Trending Technology from Data science training in btm layout experts who know advanced concepts which can help to solve any type of Real-time issues in the field of Python. Really worth trying Freelance SEO Expert in bangalore
ReplyDelete
ReplyDeleteThanks for Valuable Information man, IT was Really helpful for me.
Also, Please reach me for all types of loans - Personal loan at low interest rate in Bangalore
Trust me Its Really Worth trying for Certified mobile service center in Marathahalli
Thanks for Valuable Information man, IT was Really Fantastic.,
ReplyDeleteAlso, Please reach me for all types of loans - Personal loan at low interest rate in Bangalore
Trust me Its Really Worth trying for Certified Oneplus service center in Marathahalli
ReplyDeleteBest content.Thank you so much for sharing,i have learnt something new.I hope you will share more information like this,keep updating.
Best Data Science Certification Course in Bangalore
Gucci OG,
ReplyDeleteGorilla Glue,
Gelato Strain,
Do-Si-Dos,
Bruce Banner,
Blueberry
Mail Order Marijuana
At the point when you're attempting to get in shape, you need to ensure that your eating regimen is working for you. That is the reason you ought to be taking an enhancement called keto formation pills diet pills.
ReplyDeletehttps://deliver4superior.com/
Great blog !It is best institute.Top Training institute In chennai
ReplyDeletehttp://chennaitraining.in/oracle-dba-training-in-chennai/
http://chennaitraining.in/sql-server-dba-training-in-chennai/
http://chennaitraining.in/teradata-training-in-chennai/
http://chennaitraining.in/sap-hr-training-in-chennai/
http://chennaitraining.in/sap-fico-training-in-chennai/
http://chennaitraining.in/sap-abap-training-in-chennai/
buy exortic carts online
ReplyDeleteBuy alaskan thunderfuck
Buy gorilla glue #4 online
Buy granddaddy purple feminized seeds
Buy blue dream Weedstrain
Buy white widow weedstrain
Buy girls scourt cookies
Buy blueberry kush online
buy exortic carts online
Buy pineapple express online
Buy purple haze feminized seeds
Buy Stiizy pods online
buy exortic carts online
Buy gorilla glue #4 online
Buy Stiizy pods online
buy mario carts online
Buy white widow weedstrain
Buy bubble kush online
Buy blueberry kush online
Buy lemon haze online
Buy pineapple express online
Buy god`s gift online
Buy spacial kush online
Buy purple haze feminized seeds
buy exortic carts online
Great Content & Thanks For Sharing With oflox. Do You Want To Know How To Make Money From Mitron App
ReplyDeletehttps://k2incenseonlineheadshop.com/
ReplyDeleteinfo@k2incenseonlineheadshop.com
k2incenseonlineheadshop Buy liquid incense cheap Buy liquid incense cheap For Sale At The Best Incense Online Shop
This is nice article regarding the learning. Keep up posting the same .Get to know about best digital marketing it is.
ReplyDeleteThis is nice blog.. Keep reading about the bestdigital marketing course.
ReplyDeleteThank you so much for sharing this post.This post have important information which help user to get proper knowledge. I am also sharing Top free Guest Posting site list for improving your business online.
ReplyDeleteBuy California Driver’s License, license renewal online ca - US Driver’s License
ReplyDeleteHere at Buy Documentation, you can buy fake documents at a fraction of a cost. We keep our prices low to meet the needs of all our customers.
Buydocumentaion.com, We provide Best Quality Novelty Real and Fake IDs and Passport, Marriage Certificates and Drivers license online.
https://buydocumentation.com/document/fake-covid-test-buy-covid-19-test-results-online/
https://buydocumentation.com/buy-real-drivers-license/
https://buydocumentation.com/buy-real-id-cards/
https://buydocumentation.com/canada-visa/
https://buydocumentation.com/
Good Article. Thanks for posting this information. I was looking for this one. I have a suggestion for the Best Blogging Making Money sites. Rision Digital, Learn Tips Tricks to Succeed in Blogging and Earn Money.
ReplyDeleteBuy liquid incense cheap ,Incense for sale online offers ,Liquid Spice ,k2 chemical spray for sale , where to buy k2 near me ,K2 E-LIQUID. liquid k2 , k2 spice spray ,herbal incense for sale , Liquid Herbal Incense, cheap herbal incense , strong herbal incense for sale , Liquid k2 on paper , Liquid K2 , Legal High Incense , liquid herbal incense for sale, Order Strong Liquid Incense , Herbal Incense For Sale , Buy Vape Cartridges , Cheap K2 Spice , Legal Potpourri , Buy Herbal Incense Discrete , Legit Herbal Incense Website , Liquid Incense Overnight Delivery , Buy Potpourri With Credit Cards , buy herbal incense with debit card, , Where To Order Liquid Incense Online , Buy Liquid Incense With Bitcoin , Buy K2 Liquid Incense On Paper In USA , Strongest Incense In USA
ReplyDeleteThanks for Sharing This Article.It is very so much valuable content. I hope these Commenting lists will help to my website.
ReplyDeletegbwhatsapp
ReplyDeleteacmarket
live nettv
Hotstar mod apk
Wow such an amazing content keep it up. I have bookmarked your page to check out more informative content here.
ReplyDeleteSASVBA provides professional AI training course in Delhi with the help of industry experts. Artificial intelligence is a method of building a computer-controlled robot, computer, or software that thinks wisely as well as intelligently. It is science and technology-based on subjects such as computer science, biology, psychology, linguistics, mathematics, and engineering.
FOR MORE INFO:
The reason behind this idea is that large business owners are not comfortable activating their products individually, so Bill Gates announced a KMS server technology that allows you to connect your computer to the server.
ReplyDeleteKMSpico Official
How to Activate Windows 10 Free
RemoveWAT Activator
Windows 10 Activator
Windows Loader
Windows 8.1 Product Key
Windows 7 Activator
KMSPico Windows 10 Activator
Windows 10 Activator 2021
Windows 7 Activator 2021
Thanks a lot for sharing kind of information. Your article provides such great information with good knowledge. Digital Marketing Training in Pune
ReplyDeleteDownload OGWhatsapp Apk Most recent Rendition OG Whatsapp Give a Double Use WhatsApp
ReplyDeleteand WhatsApp OG is a mod of Ordinary WhatsApp Download, Best Highlights in This Application.
Hi Folks Welcome to OG WhatsApp download, WhatsApp Download is the world best Courier
application 500 Million,
Download OG WhatsApp Apk
Individuals use WhatsApp This application, not for Fulfillment Highlights I will
give their gathering created application
Thanks for sharing a great article.
ReplyDeleteYou are providing wonderful information, it is very useful to us.
Keep posting like this informative articles.
Thank you.
Get to know about content://com.android.browser.home
ReplyDeleteit is the best website for all of us. it provides all types of software which we need. you can visit this website.
https://chproductkey.com/
Buy Pax Era Pods
ReplyDeleteThc Vape Cartridges
Buy Thc Vape Cartridges online
Buy Pax Era Pods
Thc Vape Cartridges
Buy Infinity Kush Single Origin Pax Pod
Buy Pax Era Pods
Thc Vape Cartridges
pax era pods colorado
Buy Pax Era Pods
Buy Viper Cookies Pax Era Pod
Buy Infinity Kush Single Origin Pax Pod
Buy Pax Era Pods
Thc Vape Cartridges
Buy Thc Vape Cartridges online
Buy Pax Era Pods
Thc Vape Cartridges
Buy Infinity Kush Single Origin Pax Pod
Buy Pax Era Pods
Thc Vape Cartridges
pax era pods colorado
Buy Pax Era Pods
Buy Viper Cookies Pax Era Pod
Buy Infinity Kush Single Origin Pax Pod
A very awesome blog post. We are really grateful for your blog post. You will find a lot of approaches after visiting your post.
ReplyDeletehow to open garage door without power from outside
I was exactly searching for. Thanks for such a post and please keep it up.
ReplyDeletegarage door opener repair
I like this post, And I figure that they have a great time to peruse this post, they might take a decent site to make an information, thanks for sharing it with me.
ReplyDeleteappliance repair etobicoke
A useful post shared.
ReplyDeletegarage door cable repair
So lucky to come across your excellent blog. Your blog brings me a great deal of fun. Good luck with the site.
ReplyDeletecarson overhead door
It's always exciting to read articles from other writers and practice something from their websites.
ReplyDeleteFixadoor
This is a wonderful article, Given so much info in it, These type of articles keeps the user's interest in the website.
ReplyDeletea1 garage doors
This is my first-time visit to your blog and I am very interested in the articles that you serve. Provide enough knowledge for me.
ReplyDeletegarage door repair Pittsburgh
I am extremely delighted with this web journal. It's a useful subject. It helps me all that much to take care of a few issues.
ReplyDeletecall it spring ottawa
Your post has those facts which are not accessible from anywhere else.
ReplyDeletegarage door parts mississauga
Excellent article. The writing style which you have used in this article is very good and it made the article of better quality.
ReplyDeletegarage door repair sherwood park
I really appreciate this wonderful post that you have provided for us. I assure you this would be beneficial for most people.
ReplyDeletegarage door cable repair
Thanks for the nice blog. It was very useful for me. I'm happy I found this blog.
ReplyDeleteגדרות אלומיניום
A very awesome blog post. We are really grateful for your blog post. You will find a lot of approaches after visiting your post.
ReplyDeleteפיתוח אפליקציות לאנדרואיד
I was exactly searching for. Thanks for such a post and please keep it up.
ReplyDeleteאלסק ישראל
I like this post, And I figure that they have a great time to peruse this post, they might take a decent site to make an information, thanks for sharing it with me.
ReplyDeleteטבעות אירוסין
A useful post shared.
ReplyDeletegarage door repair pittsburgh pa
So lucky to come across your excellent blog. Your blog brings me a great deal of fun. Good luck with the site.
ReplyDelete24 hour garage
A very awesome blog post. We are really grateful for your blog post. You will find a lot of approaches after visiting your post.
ReplyDeletegreen air duct services
Excellent article. The writing style which you have used in this article is very good and it made the article of better quality.
ReplyDeleteplumbers in cleveland ohio
A very awesome blog post. We are really grateful for your blog post. You will find a lot of approaches after visiting your post.
ReplyDelete24 hr garage door repair
I was exactly searching for. Thanks for such a post and please keep it up.
ReplyDeletegarage door spring replacement north dallas
I like this post, And I figure that they have a great time to peruse this post, they might take a decent site to make an information, thanks for sharing it with me.
ReplyDeletegarage door repair philadelphia
A useful post shared.
ReplyDeleteWindow Repair Smith Glass
So lucky to come across your excellent blog. Your blog brings me a great deal of fun. Good luck with the site.
ReplyDeletegarage door installation near me
It's always exciting to read articles from other writers and practice something from their websites.
ReplyDeletegarage door spring repair
This is a wonderful article, Given so much info in it, These type of articles keeps the user's interest in the website.
ReplyDeleteair conditioning service cleveland
This is my first-time visit to your blog and I am very interested in the articles that you serve. Provide enough knowledge for me.
ReplyDeletekitchen renovation houston
This is truly the web service provider I was looking for!
ReplyDeletestorefront door repair
I am extremely delighted with this web journal. It's a useful subject. It helps me all that much to take care of a few issues.
ReplyDeletegarage doors stamford ct
Your post has those facts which are not accessible from anywhere else.
ReplyDeletebusiness intelligence consultant
can i have exotic cats as pets
ReplyDeletewhere to buy extic cats online
Tiger cubs for sale
buy ocelot kittens online
bengal kittens for sale
buy serval kittens near me
savannah kittens breeders near me
savannah kittens for sale online
buy lion cubs online
buy cheetah pets online
buy exotic pets online
lung smacker
ReplyDeletewhere to buy lung smacker weed online
lungsmacker candy for sale
buy lucky smacker weed online
lung smacker weed for sale
Blue dogshit weed strain in LA
good weed strains near me
certz smacker weed strain
Fatboy sse
lung smacker weed strains
buy lungsmacker weed online
So lucky to come across your excellent blog. Your blog brings me a great deal of fun. Good luck with the site.
ReplyDeletegarage door cable repair
Thanks for the nice blog. It was very useful for me. I'm happy I found this blog.
ReplyDeletegarage door repair Cambridge
I really appreciate this wonderful post that you have provided for us. I assure you this would be beneficial for most people.
ReplyDeletegarage door repair Markham
Excellent article. The writing style which you have used in this article is very good and it made the article of better quality.
ReplyDeletehood cleaning service pittsburgh
Your post has those facts which are not accessible from anywhere else.
ReplyDeletegarage door repair san jose
I am extremely delighted with this web journal. It's a useful subject. It helps me all that much to take care of a few issues.
ReplyDeleteBrigs Garage doors
This is truly the web service provider I was looking for!
ReplyDeletescreen door replacement
It is crucial to use statistical analysis in order to interpret data. It is well-known that small and medium enterprises in India collect a lot of data on their customers as well as their employees.
ReplyDeleteIt's always exciting to read articles from other writers and practice something from their websites.
ReplyDeletetree removal tampa fl
Nice Information I read this hope you share another ane thanks.here, is Nora our organization are providing software security and build your website and promote your brand you can go and read this:-
ReplyDeletecoinbase login |
digital marketing company
Webroot Download
I was exactly searching for. Thanks for such a post and please keep it up.
ReplyDeletecustomer reviews for glucoburn
Thanks For Sharing This Blog If You Want to find best assignment expert services now click here.pay someone to take online my exam
ReplyDeleteThis blog was very helpful, if you are searching for packers and movers in Gurgaon then visit this site packers and movers in Gurgaon
ReplyDeleteThis is truly the web service provider I was looking for!
ReplyDeleteTressanew
Mangalam pvt Ltd is one of the best wedding planner in Bhubaneswar. With one of finest wedding planning team , get married in a royal style with our expert & luxury wedding planning and destination wedding planning services.
ReplyDeleteWhere to buy glucoburn
ReplyDeleteThank you for such an inspiring blog.
ReplyDeleteThis is a wonderful piece of writing.It was really best blog. Thanking for sharing the blog which helps me more to understand. I am also sharing a post regarding packers and movers if anyone wants packers and movers in budget price please contact.
ReplyDeleteIts very interesting Blog, its very easy to understand. please share more blogs like this. I am also sharing a blog which is very helpful for people who wants better skin and health problem's Solution.
ReplyDeletePlease visitskin care by home remedies
Download WhatsApp Plus Android Free, Download the WhatsApp Plus Blue on your phone and then run the apk file to install it. https://mygbapps.com/
ReplyDeleteAmazing work please share more amazing posts like this. Thanks!STL Results Today
ReplyDeleteVery clear example of code, thanks. I advice you to post this article in Instagram so that many interested people can see it. And you can always use the services of https://viplikes.net/buy-instagram-followers in order to increase their ammount.
ReplyDeleteStrictionD is a dietary supplement made up of an advanced formula that not only controls high blood sugar but also improves insulin responses. It also fights against the causing agents of type 2 diabetes. Many Health blogs have published StrictionD reviews that endorse the efficacy of this supplement. It has been rightly called a powerful type2 diabetes destroyer and a natural cure for diabetes.
ReplyDeleteType 2 diabetes destroyer
You’d require the Spectrum WiFi Router login default credentials to log into the router admin console. Once you are done connecting the router to your computer, you can open the router login page by browsing the default IP address of the router. Lastly, provide the router login credentials and click on ‘Login’ to log into the Spectrum Router.
ReplyDeleteThe glamorous c7 pro display of its kind represents a special advantage among competitors due to Samsung's super-emulated featurehttps://vaavak.com/mag/post/2658
ReplyDeletecanon scan utility is a program that allows you to easily scan photos, documents, and other items. Simply click the corresponding icon in the IJ Scan Utility main screen to go from scanning to saving all at once.
ReplyDeletecanon scan utility is a free photography programme that lets you scan photos and documents quickly. This multimedia tool, created by Canon Inc., is a scanner software designed to work with Canon printers and scanners. It's one of the official image management programmes that you'll need to use if you're working with this brand. However, the device models that this supports are limited; some of them require the Lite version instead.
ReplyDeleteComplete Trend Micro Activation from www.trendmicro.com/activate
ReplyDeleteusing the product key. Enter your activation code and sign in to download its products. Make sure you accept the Trend micro license Agreement you receive on www.trendmicro/activate
to register your product securely. Use your Trend Micro license to protect several computers with the Trend Micro security program. Therefore, use the code through www.trendmicro.com/activate to get a full PC protection suite with security functionality after your product registration and activation. trend micro activation
While dieting, do you have a strong desire for all of the scrumptious, and delicious snacks that satisfy your taste bud? That should go without saying, right? It’s not uncommon to experience food cravings,especially when striving to maintain a balanced diet.
ReplyDeleteketo butter cookies
hp officejet pro 8600 driver is a multi-functional printer that is best for use in offices or homes. It comes with some great features like automatic document feeder and instant ink plan. So, simply you do not ever have to worry about empty ink cartridges. other than this, the automatic document feeder will detect, scan and copy different documents on its own.
ReplyDeleteHp printer repair provides you 24x7 services where you can repair your hp and we provides better services than other companies and may resolve your problems in minimum times.
ReplyDeletePrinter in error state” message comes up in a popup box on the desktop screen when the user tries to connect to the device or print from the device. Error codes like this may appear for a variety of reasons, but they are most often caused by a recent software update such as Windows Update that interferes with communication between the system and the attached printer.
ReplyDeleteA cannon printer is used for home and office.It is compatible with every major operating system including windows,androids and ios. It will also give best quality and speed when printing document.
ReplyDeleteij.start.cannon
Except How to travel in pregnancy? This question is basically traveling or not to travel in pregnancy. Allow traveling at any age of pregnancy and generally all over pregnancy with a doctor. If you https://7ganj.ir/%da%86%da%af%d9%88%d9%86%d9%87-%d8%af%d8%b1-%d8%a8%d8%a7%d8%b1%d8%af%d8%a7%d8%b1%db%8c-%d8%b3%d9%81%d8%b1-%da%a9%d9%86%db%8c%d9%85%d8%9f/ have high pregnancies, if you have a severe situation in pregnancy, and in general, if your pregnancy condition is not a normal and natural condition, the best thing is to travel during pregnancy and wait until your first trip after pregnancy. Experience with your child's child.
ReplyDeleteTokens issued through an initial DEX proposal (IDO) DEXs are decentralized exchanges, meaning they use blockchain technology to boost exchanges rather than a centralized entity such as Coinbase or https://www.golchinonline.ir/index.php/newposts/news/6344-%D8%A8%D8%B1%D8%B1%D8%B3%DB%8C-%D8%A7%D8%B1%D8%B2-%D8%AF%DB%8C%D8%AC%DB%8C%D8%AA%D8%A7%D9%84-%D8%A7%D9%84%D9%88%D9%86.html Robinhood. Given that the maximum initial supply is 1 quadrillion tokens. So do not expect Alon's currency to reach close to $ 1 any time soon.
ReplyDeleteAmazing work please share more amazing posts like this. Thanks!https://todayswertreshearing.com
ReplyDeletehttps://todayswertreshearing.com
ReplyDelete
ReplyDeleteEpson printers are one of the most advanced printers available today. However, many Epson printer drivers are experiencing problems with their printer when they try to print anything with their Epson printer For all such issues, you need not worry and keep your hopes on us. We will let you go through the troubleshooting methods of different Epson Printer issues. Epson printer troubleshooting will you for this issues.
How to connect canon mg3620 printer to wifi , The Canon PIXMA MG3620 is a wireless inkjet across the board printer that is helpfully little, snappy, straightforward, and doesn't think twice about execution or quality. The remote capacity takes into account printing anyplace in the house or office. Furthermore, cell phone printing and auto duplex printing set aside time and cash.
ReplyDelete
ReplyDeletetenorshare 4ukey“Fortune favors the bold.” – Virgil.
“I think, therefore I am.” – René Descartes.
“Time is money.” – ...
“I came, I saw, I conquered.” – ...
“When life gives you lemons, make lemonade.” – ...
“Practice makes perfect.” – ...
“Knowledge is power.” – ...
directory opus pro crackquote Add to list Share. ... As a verb, to quote means to repeat someone's words, attributing them to their originator. If you're giving a speech on personal organization, you might want to quote Ben Franklin in it — he's the master.
ReplyDeleteFacebook has the option of creating a poll. If you are wondering, how do I make a poll on Facebook. Open your group chat and then tap on the plus sign at the bottom of the window. You will be directed to a new window. Here, you can select the Facebook poll icon and type your question. Then, add your options and tap to create a poll. You can follow these simple steps and post it.
ReplyDeleteVISIT HERE: https://article.raghavchugh.com/how-to-take-a-screen-shot-on-facebook/
https://www.apsense.com/article/how-to-access-juno-email.html
https://evajones9837.medium.com/what-to-do-if-you-are-unable-to-log-in-to-juno-email-d5fc2c8358ca
New year has come and so also the time of new assignments. The troubles might have just started but it's going to continue till long. I too faced it while I was in my graduation days, but thanks to greatassignmenthelper.com every thing got completed just by paying a little cost. Their online Assignment Help was so nice that working with him was like talking to my colleagues.
ReplyDeleteThank you for shering amazing post this is post very usefull for me.
ReplyDelete[url=https://www.clayie.com/]Online Garen Store[/url]
[url=https://www.clayie.com/product/cute-panda-pot-339761]Buy Cute Panda Pot[/url]
[url=https://www.clayie.com/product/cocopeat-powder-2kg-585625]Buy Cocopeat Powder 2Kg[/url]
[url=https://www.clayie.com/product/ludo-dice-ceramic-pot-659749]Buy Ludo Dice Ceramic Pot and Stands[/url]
[url=https://www.clayie.com/product/antique-brass-planter-set-of-2-863491]Buy Antique Brass Planter Set Of 2[/url]
[url=https://www.clayie.com/product/wall-decor-basket-cycle-832200]Buy Wall Decor Basket Cycle[/url]
blueberry-strain
ReplyDeletegrape-ape-strain
critical-kush-strain
vanilla-kush-strain
chronic-thunder-strain
jack-herer-strain
incredible-hulk-strain
green-crack-strain
durban-poison-strain
harlequin-strain
Thanks for the nice information. Here if you want to know what is twitter trend. then read the article below.
ReplyDeleteWhat is Twitter Trend.
Thanks For sharing such valuable information. Really it is a great post.
ReplyDelete[pii_email_e147cf3510887c53b5ed]
Buy Immersion Rod Online At Best Price in India
ReplyDeleteVisit multiple websites to compare immersion rod prices and buy immersion rod. If you want to buy an immersion rod at less price, contact us. KENSTAR has affordable appliances for your house.
immersion rod
Nice website. Love it. This is really nice.
ReplyDeletelocast.org/activate
hbomax/tvsignin
disneyplus.com/begin
showtimeanytime.com/activate
This is really nice.
ReplyDeleteHbomax/tvsignin
Disneyplus.com/Begin
Disneyplus com login begin
Cricut.com/setup
this is awesome stuff thank you for sharing
ReplyDeletegreat information!
ReplyDelete
ReplyDeleteReally it is a very nice topic and Very significant Information for us, I have think the representation of this
Information is actually super one.Property Dealers In Janakpuri.
We believe every puppy deserves a home and every dog lover deserves the best..
ReplyDeletewelcome to Maltese Puppies
where to buy Maltese Puppies
Maltese puppies
Maltese Puppies For Sale
We are really grateful for your blog post. You will find a lot of approaches after visiting your post. Great work
ReplyDeletedata science training
Our Data Science certification training with a unique curriculum and methodology helps you to get placed in top-notch companies. Avail all the benefits and become a champion.
ReplyDeletedata scientist certification malaysia
review StrictionBP weight loss Angourie
ReplyDeletesm3ha
ReplyDeletex2download
bagishared
bagishared
mxtube
mxtube
bokep indo
bokep indo
bokep hd
bokep indo
such a nice and amazing post which I have never seen before thanks for sharing this info and I also like to share with you this mini militia apk which you can play with your friends..
ReplyDeleteA very awesome blog post. We are really grateful for your blog post. You will find a lot of approaches after visiting your post.
ReplyDeletelean six sigma santa fe
I really appreciate this wonderful post that you have provided for us. I assure you this would be beneficial for most people.
ReplyDeletelas cruces lean six sigma history
It's always exciting to read articles from other writers and practice something from their websites.
ReplyDeletehttps://www.deckbuildersraleighnc.com/sunrooms-raleigh
I am extremely delighted with this web journal. It's a useful subject. It helps me all that much to take care of a few issues.
ReplyDeleteconcrete contractor dayton ohio
So lucky to come across your excellent blog. Your blog brings me a great deal of fun. Good luck with the site.
ReplyDeleteyellow belt certification fayetteville
Your blog brings me a great deal of fun. Good luck with the site.
ReplyDeletemicro improvement system training
Good luck with the site.
ReplyDeleteretaining walls loxahatchee
Thanks for sharing this information. Good luck with the site.
ReplyDeletewe buy houses pennsylvania
Thanks for sharing this information. Good luck with the site.
ReplyDeletewww.landscapinginelpaso.com/tree-service
betmatik
ReplyDeletekralbet
betpark
mobil ödeme bahis
tipobet
slot siteleri
kibris bahis siteleri
poker siteleri
bonus veren siteler
OD1XH
Not so accurate, but still enjoyed it. thanks.
ReplyDeletewe buy houses for cash milwaukee
Interesting read, can i share this on my blog?
ReplyDeletesell my house fast in pennsylvania
Interesting read, can i share this on my blog?
ReplyDeletesell my house fast new orleans
شركة صيانة افران بجدة
ReplyDeleteصيانة افران بجدة
even I also think that hard work is the most important aspect of getting success.
ReplyDeleteYou make so many great points here that I read your article a couple of times.
ReplyDeleteI appreciate your skills and style in elaborating on the topic.
ReplyDeleteIt’s always nice when you can not only be informed, but also entertained!
ReplyDeleteThank you for the share.. D.
ReplyDeleteCan’t thank you enough! D.
ReplyDeleteKeep up the amazing work…D.
ReplyDeleteشركة صيانة افران بمكة
ReplyDeleteiPRoWHhnA9
شركة تنظيف بجده
ReplyDeleteV0Jvrpb9IVmR
ReplyDeleteYour writing is impressive. thank you
ReplyDeleteI want to write like you thank you
ReplyDeleteHi! this is often nice article you shared with great information.
ReplyDeleteThanks designed for sharing such a pleasant thinking, piece of writing is good
ReplyDeletethats why i have read it entirely thank you
I subscribed to your blog and shared this on my Facebook.
ReplyDeleteThanks again for a great article!
ReplyDeleteThis sort of clever work and reporting!
ReplyDeleteKeep up the superb works guys I've included you guys to my blogroll.
ReplyDeleteSalesforce admin training covers complete administration tasks including automation and security management. It explains dashboard creation and workflow rules clearly. This salesforce admin training enhances CRM management and reporting expertise. Learners gain hands-on project exposure. Practical assignments are included. Expert mentorship is provided. It prepares successful Salesforce professionals.
ReplyDelete“Excellent insights! Our ui ux classes
ReplyDeletecourse helps you build practical skills in responsive design, usability, and interface design.”